The amount of administrative tasks in today's workplace is steadily growing, whether you are a manager or just driven by requirements from management for more and more reports. The introduction of IT into these processes held the big potential of easing some of the tedious tasks through automatization and integration, but it seems that we are still a long way away from that goal. Segregated toolchains, lack of compatibility of interfaces and different work cultures combined with the increased amount of communication have resulted in an increase of stress and drudgery. Dealing with the fallout often requires substantial manual effort, frequently in a form which is not reusable and sustainable.
What can we as scientists and software engineers do to improve our situation? I am asking this in the most pragmatic sense and I will describe what I found over the last years to work for me. So, this is not about demanding that the world suddenly becomes perfect and reasonable by magically establishing compatible standards and adopt harmonized best practices agreed on by everyone - this will not happen. I just want to demonstrate that we can just use our knowledge from science and engineering and combine them smartly with existing frameworks. My own background is in physical chemistry with long years working in scientific computing, so management is for me another acquired skill which I had to grow into (and sometimes I still feel baffled by some of the concepts…).
So let's see what we can do based on the toolchains that we learn in data science and software engineering. I will use GNU Emacs to present my current workflow, but the ideas are generic and you may find other solutions.
If you are just interested into the Emacs workflow using my new package org-listcruncher you can just scroll down to the example section.
1 The problem
The sad reality is that a lot of management document methodology comes in the form of Excel and Powerpoint documents. While I think that Excel is a good piece of software for enabling people to obtain results fast and in a nicely interactive way, it's work model for complex or long-lived documents is definitely sub-optimal.
Reasons
- changes to the document are difficult to track in a transparent and comprehensible way. Compare this to the established way we track software changes in revision control systems like git. There we not only track each change, but also the motivations for it.
- as the Excel documents gets bigger, it tends to contain many sheets with lots of references. Errors easily creep in and are difficult to spot (e.g. numbers outside of formula cell ranges which are silently ignored). Compare this to unit tests and integration tests that we use continually in software development and scientific programming.
- there is a lot of copy & paste going on, from the Excel sheet into a word document used as a report, to a Powerpoint to do a presentation. In data science we also take care to track the changes to data (data provenance) and to make sure that a document references a dataset in a clearly identifyable way.
2 What we want
Let's take as an example the planning of a complex budget over several years.
- We would like to have way to put down our budget entries in a form which allows adding comments and other meta data to explain the entry.
- When we get improved forecast information, we would like to be able and override previous information without deleting it, so that an audit trail is conserved.
- The format in which we write down all of this information should lend itself to automatically generate a data set that can be manipulated with state of the art tools.
- The code producing the budget forecasts and plots should be a part of the document, so that we can hand it to somebody else, and she can easily understand how we came to the numbers.
- The format should be easily manageable by standard revision control systems, so that we can nicely document the changes over time.
- Produce beautiful and readable documents in a mostly automatic way for optimal readability.
- Since our management very often desires Excel or other formats, we would also like to be able and export to these other formats as well… but all from the same source.
3 Three Musketeers to the Rescue
3.1 Reproducible Research
Reproducible research is an important topic in today's IT research and it also has a big significance for our society and the ethics of conducting research. It is important to keep the underlying data, algorithms, and argumentation, so that others can follow the analysis of the data and understand the conclusions. Today's interest in SW containers like Docker is apart from being a great deployment mechanism also powered by this desire to allow the conservation of computational environments in an easily sharable form.
The concept of Reproducible research is closely related to the idea of literate programing that Donald Knuth launched with his seminal article in 1984. Literate programming environments allow the free mixing of code parts with extensive documentation parts. The source of a literate programming document contains all necessary data as well as the code for manipulating the data to produce results and plots. It also contains all the text and argumentation. Out of this source document one then can generate a nice publication, but also other derived information (e.g. a standalone software program and a data set, or an excel sheet to give to management).
Org mode for Emacs is one such environment, but there are also others (e.g. look at this list of links maintained by reproducibleresearch.net). Another open source environment in rapid development is given by Jupyter notebooks. They are very popular among scientists. These frameworks are not only great for publishing research in a reproducible manner, but also are becoming one of the best teaching aids, since students can easily experiment with self-contained documents.
3.2 Software Best Practices
Changes of source code should be tracked by revision control systems (RCS) like git. An optimal tracking is possible, if the differences from one version of a document to the next can be easily visualized. This usually requires that the document format is in a text based format and not some closed binary format. The RCS help us to track changes through time, and we also can add metadata in the form of comments to explain the motivations for the changes.
Humans will make errors, and each time one does something non-trivial, especially when it is of a repetitive nature, errors easily creep in. Also, doing changes in one part of a complex thing may cause other parts of our wonderful ivory tower computation to collapse. So, in SW engineering the ideas of unit and intergration tests has become an accepted paradigm.
Versioning. Documents should be versioned in a clearly defined way similar as to what we do with widely accepted standards like semantic versioning.
Templating and Repetition Repetitive parts in a document, e.g. if for a budget of many services a certain basic text/table/graphics structure needs to be repeated multiple times, we would like to generate it by a single code block that we call with different arguments - and not by copy/paste and manual editing. Senseless repetition or copy/paste is useless human toil and leads to errors. later changes to the basic structure should not involve us in making changes in a hundered places.
3.3 Data Analysis Tools
There exists a plethora of programming languages and libraries to deal with data in all of its forms. In particular, Python is a language which has found increasing adoption by the scientific community over the last decade. It is expressive and provides a wealth of libraries and also frameworks for interactive data analysis. Naturally there are other solutions as well, e.g. the R project.
Since I am a Python person, I will recommend the following libraries for tackling the kind of management related problems we are talking about
- Pandas: easy-to-use data structures and data analysis tools
- numpy: fundamental package for scientific computing. Used by Pandas
- matplotlib and seaborn for visualization
4 An example workflow using Emacs Org mode and python
In the following I will demonstrate my own planning workflow that I built up over the last years using Emacs and its fabulous Org-Mode.
Emacs is a fantastic environment for programmers, since the whole editor is an extensible lisp environment with a vibrant community producing new packages.
4.1 Plan using an outliner
Outliners are ideal for jotting down thoughts and ideas. Some people may prefer mind-maps, but in the end the underlying data structures are mostly identical. The outliner lists are certainly more efficient for a proficient typist and are easily mixed with other parts of a text.
I have used outlines for years for the initial planning of most tasks. Actually the approach is now so engrained with me that I use lists as the starting point for almost all documents I write. Their inherent simple structure allows to express the main ideas as top level items, and then use Sub-items to further refine them or add newer information in a way that is transparent.
I also have used this approach for drawing up project and service budgets for our scientific computing section over the last years, But only now I implemented a better way to automatically derive a useful data structure from such a list in a new Emacs package org-listcruncher (you can get the package from MELPA).
Here is an example of a planning list for a budget of two (non-IT) services.
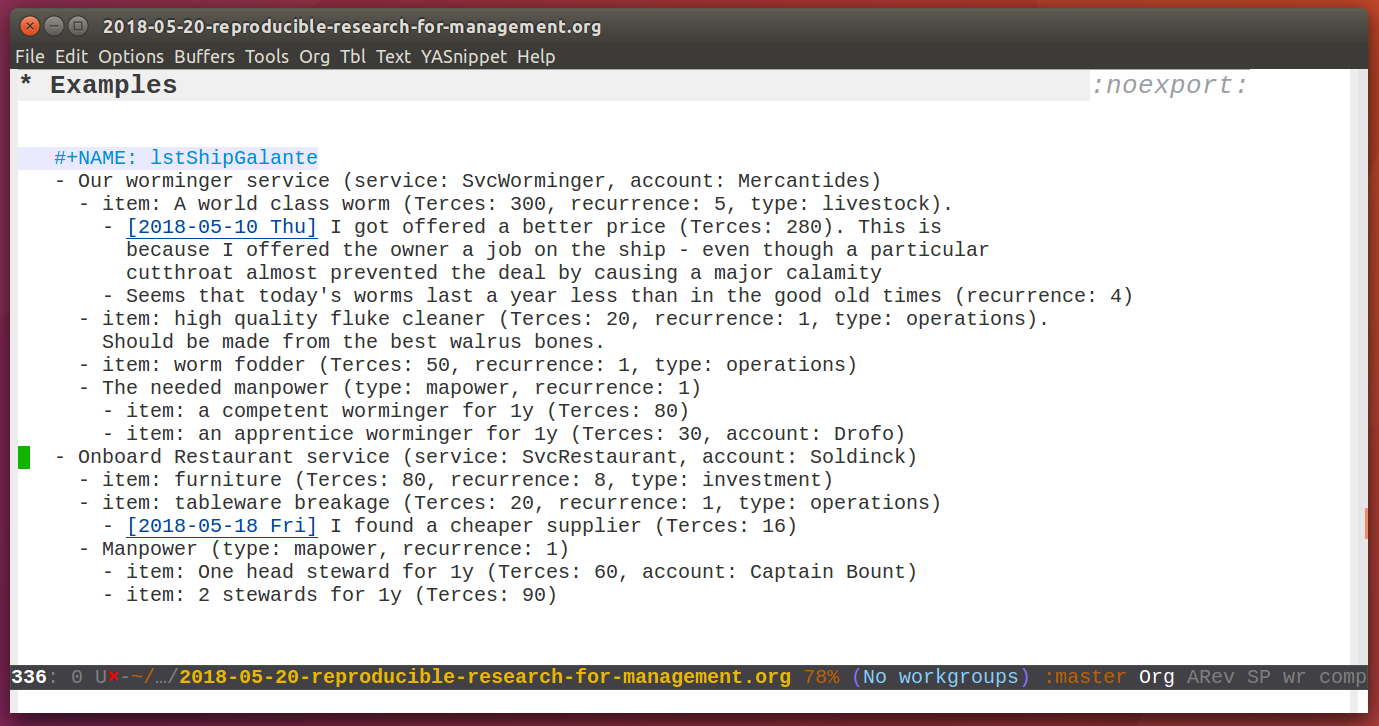
My rules for writing such a planning list are
- Each line contains a tag defining wheter the line will become a table row. For this example I defined this as the string "item:". Rows without such a tag just serve as metadata.
- A string following the output tag "item:" is taken as the description of the table row.
- Each line can contain any number of key/value pairs in parentheses in the form
(key1: val1, key2: val2, ...) - Lines of lower hierarchical order in the list inherit their default settings for key/values from the upper items.
- The key value of a higher order item can be overwritten by a new new value for the same key in a lower order line.
Note that org-listcruncher allows the user to supply an own parsing function, so the rules for how the key/values, the description, and the tagging for a row can get arbitrarily defined by the end user. The present default function is just an easy example.
One can easily imagine using the same kind of approach to derive a table of ingredients and their amounts from the instructions of a cooking recipe that is given as a sequential list of steps. Just needs a bit a smarter parsing function.
4.2 Generate a table from the outline
We now would like to derive from the planning list a more suitable data format for doing computations. A table is an optimal format. The main function of org-listcruncher provides just this conversion. Based on the semantics defined in the previous section.
The following Org mode code block contains a single line of Emacs
lisp for calling org-listcruncher's main function and uses the
above list (which I named lstShipGalante) to create a table based
on an "outer join" of all the keys found with the respective values
arranged in columns.
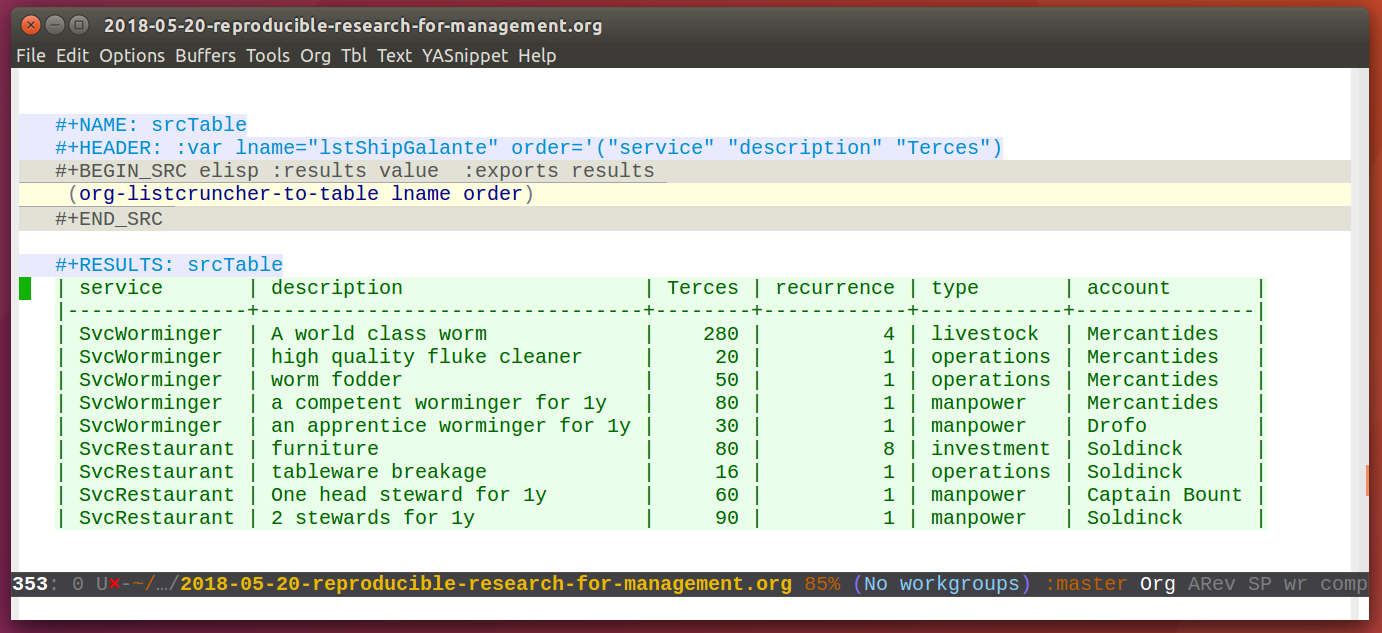
The list from which we generate the table can later be further edited, and all derived results will change accordingly when recalculating the whole document. The audit trail is conserved in the list itself through the comments, and naturally it will also be conserved in the commits into the revision control system.
4.3 Data analysis and visualization
Now, as the data is in an easily accessible form, we can use Org mode's Babel feature to read in the table into a python code block and perform some Pandas data manipulation magic on it.
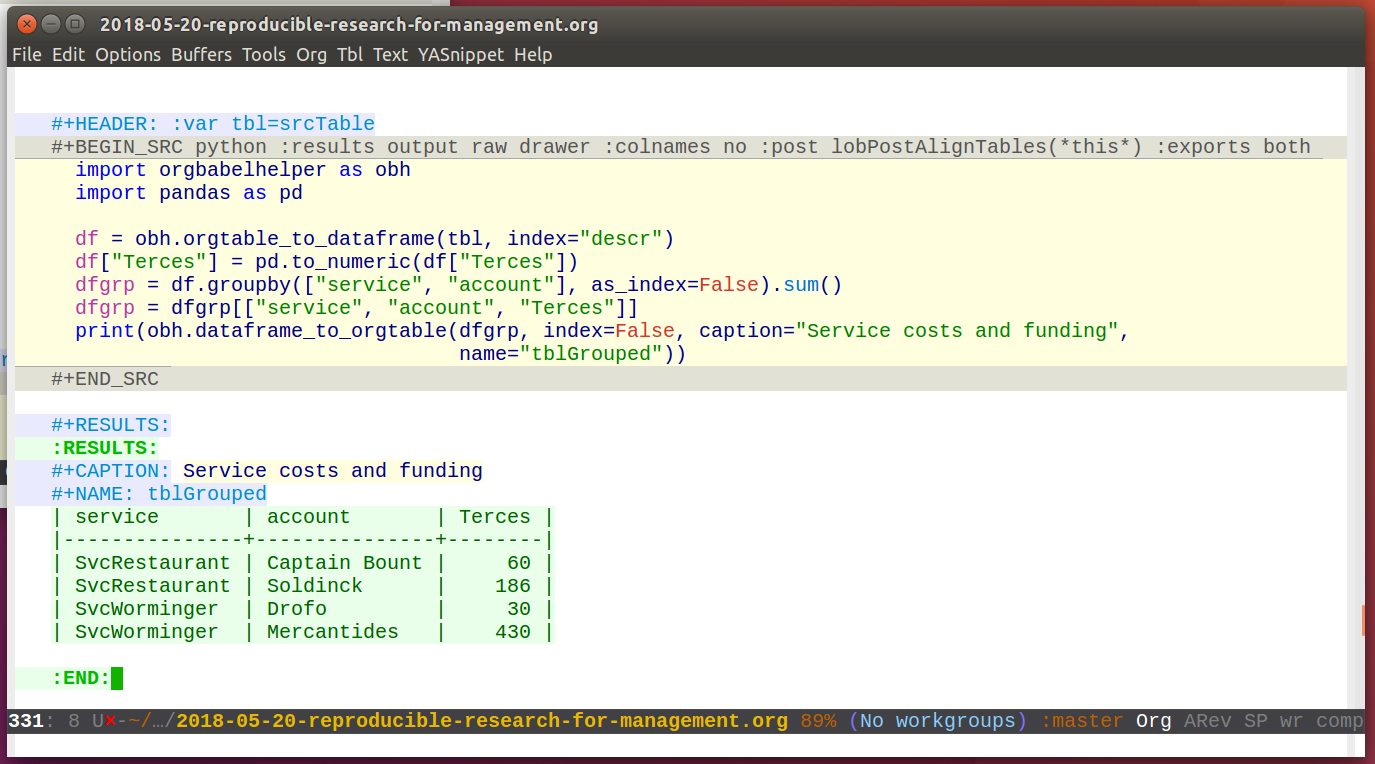
And another little code block lets us visualize cuts of the data with matplotlib and seaborn.
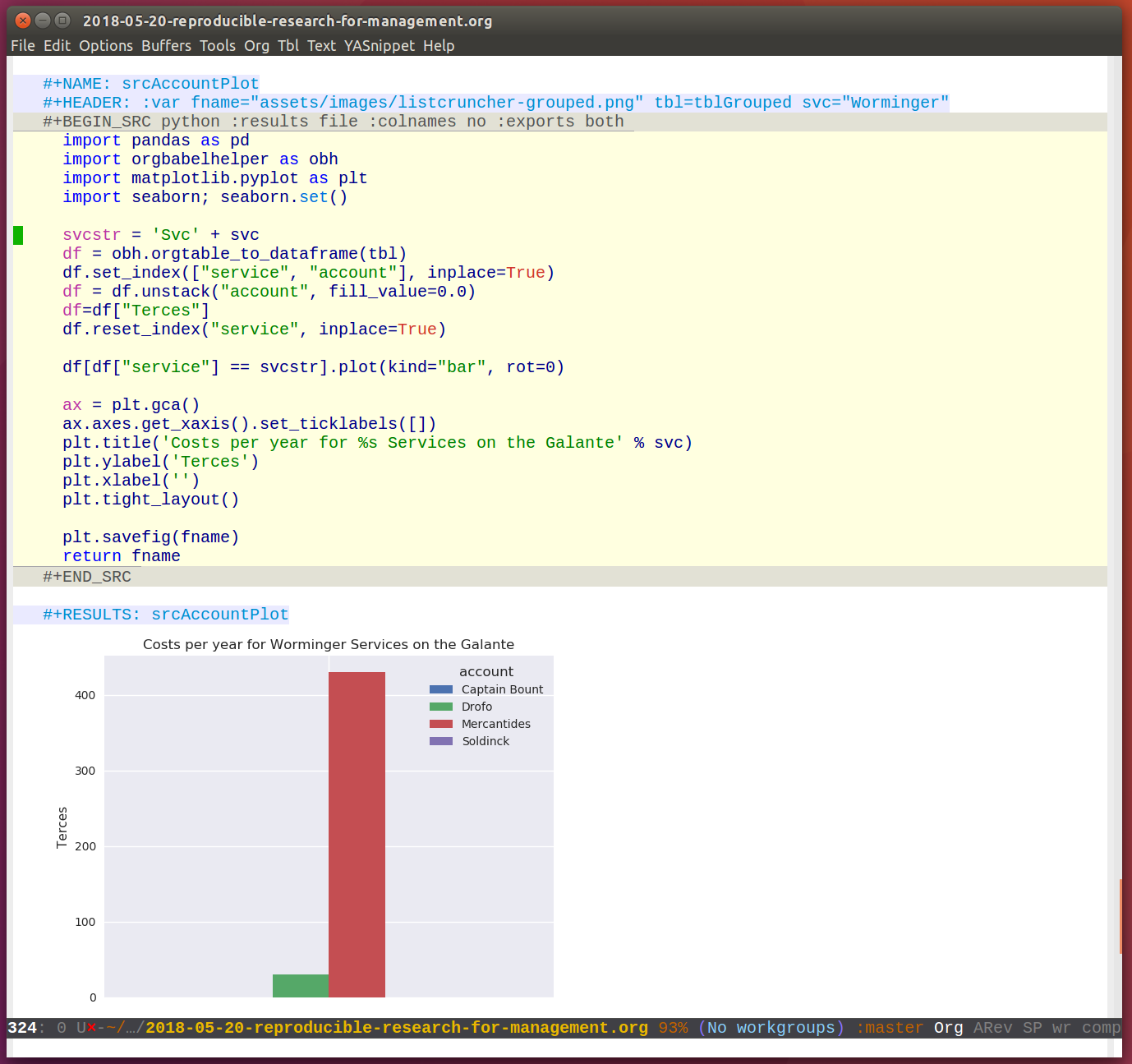
And we can generate the plots for our report.
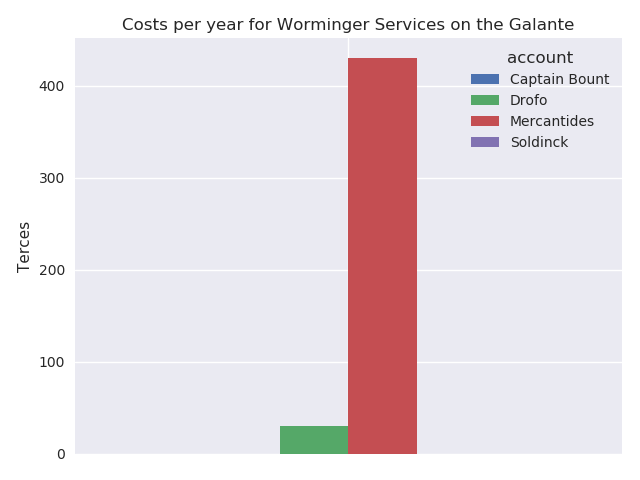
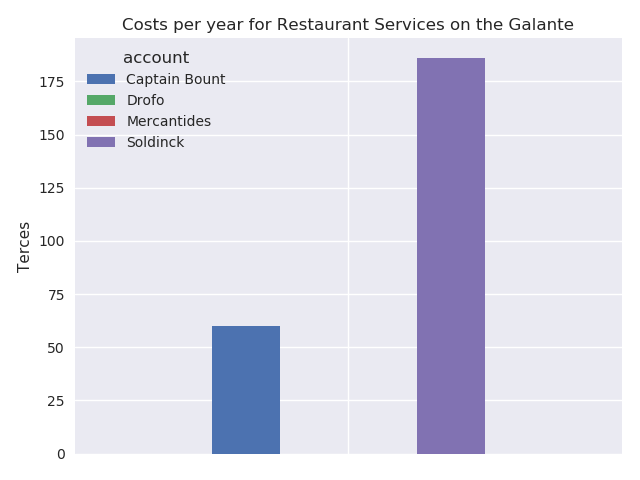
4.4 Versioning, templates, testing
I will only refer cursorily how to address the other points
- Org mode is part of Emacs which offers a number of powerful templating systems. Org itself supports Macros which can generate text parts.
- Versioning can easily be combined with org mode documents and integrated in the common ways with revision control systems like git (e.g. via tags)
- testing: Since org offers native inclusion of code snippets in different programming languages, tests can easily be formulated in the avaible test frameworks of these languages. One can also define simple tests in form of document code blocks putting out warnings into the document.
5 References
- Emacs Org mode
- Babel is Org-mode's ability to execute source code within Org-mode documents
- Please appreciate that there is a big number of Open Source programmers tending to the Emacs / Org Mode and Babel ecosystem.
- My own gitub repository of babel examples
- also shows how examples for producing nice documents by exporting through Latex and Beamer: Latex report PDF example, Beamer PDF example
- org-listcruncher for parsing Org mode lists into tables
Fabrice Niessen's nice Org Babel reference card. I also am using his Emacs leuven theme and he has some nice CSS for high quality Org mode to HTML exporting.
This blog post is itself a HTML exported Org document that also began its life as a simple list. You can have a look at its source code on github. The Jenkins blogging framework is then used to add some finishing touches for the blog's theme.
6 Publishing
- I submitted to reddit under https://redd.it/8kvvz8
- thanks to jcs from the Irreal blog for reviewing and pointing to my article: http://irreal.org/blog/?p=7216
- thanks to Sacha Chua for including it in her Emacs news http://sachachua.com/blog/2018/05/2018-05-21-emacs-news/